Suggested Videos:
Part 1 - How to find nth highest salary in sql
Part 2 - SQL query to get organization hierarchy
Part 3 - How does a recursive CTE work
In this video, we will discuss deleting all duplicate rows except one from a sql server table.
Let me explain what we want to achieve. We will be using Employees table for this demo.
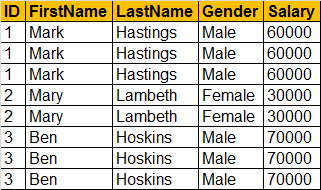
SQL Script to create Employees table
The delete query should delete all duplicate rows except one. The output should be as shown below, after the delete query is executed.

Here is the SQL query that does the job. PARTITION BY divides the query result set into partitions.

Part 1 - How to find nth highest salary in sql
Part 2 - SQL query to get organization hierarchy
Part 3 - How does a recursive CTE work
In this video, we will discuss deleting all duplicate rows except one from a sql server table.
Let me explain what we want to achieve. We will be using Employees table for this demo.
SQL Script to create Employees table
Create table Employees
(
ID int,
FirstName nvarchar(50),
LastName nvarchar(50),
Gender nvarchar(50),
Salary int
)
GO
Insert into Employees values (1, 'Mark', 'Hastings', 'Male', 60000)
Insert into Employees values (1, 'Mark', 'Hastings', 'Male', 60000)
Insert into Employees values (1, 'Mark', 'Hastings', 'Male', 60000)
Insert into Employees values (2, 'Mary', 'Lambeth', 'Female', 30000)
Insert into Employees values (2, 'Mary', 'Lambeth', 'Female', 30000)
Insert into Employees values (3, 'Ben', 'Hoskins', 'Male', 70000)
Insert into Employees values (3, 'Ben', 'Hoskins', 'Male', 70000)
Insert into Employees values (3, 'Ben', 'Hoskins', 'Male', 70000)
The delete query should delete all duplicate rows except one. The output should be as shown below, after the delete query is executed.
Here is the SQL query that does the job. PARTITION BY divides the query result set into partitions.
WITH
EmployeesCTE AS
(
SELECT *, ROW_NUMBER()OVER(PARTITION BY ID ORDER BY ID) AS RowNumber
FROM
Employees
)
DELETE FROM EmployeesCTE WHERE
RowNumber > 1
SELECT * FROM Employees
ReplyDelete-- Delete duplicate rows in sql
SELECT DISTINCT ID,FirstName,LastName,Gender,Salary
FROM
Employees
SELECT DISTINCT * FROM Employees
Deletethis work also
ReplyDeleteDELETE FROM Employees WHERE id NOT IN
(SELECT MIN(id) FROM Employees
GROUP BY FirstName,LastName,Gender,Salary)
useful when id is primary key
DeleteWill not work as you cant have Min(ID) in select clause, when its not in Group By clause
Deletecheck this please
ReplyDeleteSELECT DISTINCT * INTO tblEmployee5
FROM tblEmployee
DROP TABLE tblEmployee
EXEC sp_rename 'tblEmployee5', 'tblEmployee'
Hi Venkat,
ReplyDeleteCan you pls explain how to delete rows except one based on only some column values?
eg Employees table having FirstName, LastName, Salary & City column.
I want to delete all rows except one with FirstName, LastName and City duplicate having salary different.
Thanks in advance.
Run this query, it will clear a lot about Rank, DenseRank and RowNumber
ReplyDeleteselect ID, ROW_NUMBER() OVER (partition by ID Order By Id desc) as RowNumberCol,
RANK() OVER(Order By Id desc) as RankCol,
DENSE_RANK() OVER(Order By Id desc) as DenseRankCol
from Employees
i want to use this query in fronnt end .in c# or asp.net forms..plz help me.how to use
ReplyDeleteExcellent .. Great .... Thank you so much
ReplyDeleteIn Mysql getting error
ReplyDeleteTable 'test.employeescte' doesn't exist
Can anyone help me how can i delete duplicate rows in mysql ?
That's because you don't have the table "test.employeescte" . It says "doesn't exist". The table called "employeescte" belongs to author's database(as an example). So you must replace the code with your table name which has duplicated rows. Don't forget to replace "test" with your name of database.
ReplyDeletelets think about your scenario change
ReplyDelete1) if there is multiple duplicate rows in table base on Name example :
(1, 'Mark', 'Hastings', 'Male', 60000)
(2, 'Mark', 'Hastings', 'Male', 50000)
(3, 'Mark', 'Hastings', 'Male', 80000)
from this duplicate rows just keep highest salary values row only and others delete?
2) if there is multiple duplicate rows in table base on Name example :
(1, 'Mark', 'Hastings', 'Male', 60000)
(2, 'Mark', 'Hastings', 'Male', 60000)
from this duplicate rows just keep latest ID values row only and delete others rows?
with cte_emp as
Delete(
select *, row_number() over (partition by firstname order by salary desc) as orderid
from employees
)
delete from cte_emp where orderid > 1
with cte_emp as
Delete(
select *, row_number() over (partition by firstname order by salary desc) as orderid
from employees
)
delete from cte_emp where orderid > 1
select * from employees